第一次用RobotFramework-SeleniumLibrary写网页的GUI测试,封装关键字,按功能模块划分关键字。后来一次系统层面的UI重构,所有用例要重新写,成本很大,遂找到2013年提出,2015成熟的Page Object设计模式。基于页面或重用组件封装,仅将人类能交互的操作封装为方法。抽象后,可读性、可维护性大增。
Docker 运行 Jenkins 无法显示报告
Docker运行Jenkins有诸多不便,尽量不要使用。
较新版本Jenkins限制了js和css的运行,然而RobotFramework的日志log.html和报告report.html都严重依赖js和css。docker平台上最简单解决方法就是用JAVA_OPTS-Dhudson.model.DirectoryBrowserSupport.CSP=,放松Jenkins的安全策略。缺失字体库会造成显示成方块的问题
Hadoop2.x 组件运维命令
Hadoop组件运维命令
TODO
Agent在supervise的方式下启动,如果进程死掉会被系统立即重启,以提供服务。
简介
项目中初次使用原生的Hadoop集群,各组件不稳定,常需要各种重启命令。
Hadoop 2.7
应该按照下文的顺序启动集群,更详细的说明请参考# HA 模式下的 Hadoop+ZooKeeper+HBase 启动顺序
- ZooKeeper
节点规划中,zookeeper跟journalnode放在一起,共5个节点1
2zkServer.sh start # QuorumPeerMain
hadoop-daemon.sh start journalnode # JournalNode - 启动NameNode
1
hadoop-daemon.sh start namenode
- 启动DataNode
1
2hadoop-daemon.sh start datanode # 单个
hadoop-daemons.sh start datanode # 整个集群 - 启动ResourceManager
1
yarn-daemon.sh start resourcemanager
- 启动NodeManager
1
2yarn-daemon.sh start nodemanager # 单个
yarn-daemons.sh start nodemanager # 整个集群 - 启动zkfc(DFSZKFailoverController) - HA两台master都要
1
hadoop-daemon.sh start zkfc
- 启动JobHistoryServer
1
mr-jobhistory-daemon.sh start historyserver
- 切换Active的NameNode
1
hdfs haadmin -failover nn2 nn1
- 查看hdfs状态
1
hdfs haadmin -getServiceState nn1
- 切换Active的ResourceManager
由于yarn rmadmin不支持-failover命令,只能kill掉active的ResourceManager进程,待切换后再查看
1 | yarn rmadmin -getServiceState rm1 #查看状态 |
nn1是namenode1,nn2是namenode2. 对应的配置文件是hdfs-site.xml
- 平衡
参考文章:
原因
参数
算法
任意节点执行: dfsadmin -setBalancerBandwidth 10485760 (=10MB/s)
该命令会在两个NameNode节点生效. 后续执行 hdfs balancer 会快很多.
默认是每个DataNode节点是1MB/s
生产环境点对点大约是60MB/s, 这样配置大约会占用六分之一的带宽.
不要再设置更大了, 因为多对机器传输累积到网关的速度就很大了.
hdfs balancer命令原本设计是常驻后台进程, 所以默认参数平衡时很慢的. 适用于长期运行, 不影响业务操作. 无限期后台hdfs balancer -idleiterations -1
1 | dfsadmin -setBalancerBandwidth 10485760 |
Hbase
- 启动HMaster
1
hbase-daemon.sh start master
- 启动HRegionServer
1
2hbase-daemon.sh start regionserver # 单个
hbase-daemons.sh start regionserver # 整个集群
Hive
- 启动Metastore
1
2
3# hive --service metastore # 关键部分
nohup hive --service metastore > /home/hadoop/soft/hive/logs/metastore.log 2>&1 & - 启动HiveServer2
1
2
3# hive --service hiveserver2 # 关键部分
nohup hive --service hiveserver2 > /home/hadoop/soft/hive/logs/hiveserver2.log 2>&1 &
presto
coordinator和worker都是一样的启动命令
1 | /home/hadoop/soft/presto/bin/launcher start |
Azkaban
Azkaban工作流项目使用的是2.5.0版本,有Web和Executor两个组件
1 | cd /home/hadoop/soft/azkaban-web-2.5.0/ |
Kylin
1 | cd /home/hadoop/soft/kylin/bin |
Hue
1 | cd /home/hadoop/soft/hue |
杀掉yarn上的任务
1 | bin/yarn application -kill <applicationId> |
统计hive数据仓库表占用空间
1 | #!/usr/bin/env python |
hadoop mapreduce Job Name指定任务名
sqoop参数
sqoop export/import -Dmapreduce.job.name=”<你指定的任务名>”
参考
AILog:智能化测试计划与方案
最终项目夭折了,原因在于选型会议选择了另外一个工具基础上二次开发,另外一个原因是其实本身没有那么多自动化用例的日志可供分析。我们不是平台部门,是个小业务部门
日志大数据笔记
背景
测试岗位却不甘止步于业务测试,遂尝试智能化测试,当前的思路是通过日志大数据分析,协助自动化用例的诊断和建议。
他山之石
《从日志统计到大数据分析》
知乎专栏作家桑文锋[http://SensorsData.cn](https://link.zhihu.com/?
target=http%3A//SensorsData.cn) 神策数据创始人&CEO
数据处理流程图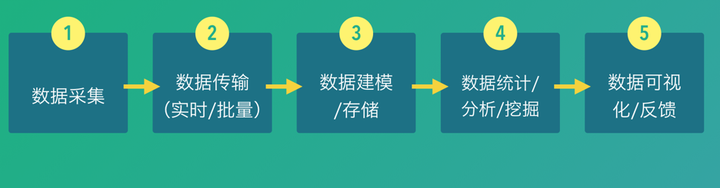
数据采集
- 全
多个来源、C/S(B/S) - 细
多个维度,ip、url、时间、userid等等尽可能多 - 数据格式
- Protocol Buffer:Google使用,较为重型
- JSON:学习成本低
- Thrift——由Facebook开源的一套开发框架和数据格式,相比PB,在解析效率上低点,但周边组件比较完善。
- Avro——由Hadoop创始人Doug Cutting主导开发的,使用接口上和Thrift类似,有客户公司在使用。
在简单看看文档后,估计会使用json。
- 数据类型
被测应用自身日志、环境日志(cpu、容器内env)、测试脚本日志;
应用代码、测试脚本(代码本身)
数据库数据?
数据传输
【这段完全照抄】
1,FTP:数据量小且时效性要求不高,用FTP是最省事的。
2,Sqoop:用于传统数据库和Hadoop之间的数据传输。3,Scribe:Facebook开源的一套日志传输系统,github上已经不维护了。
4,Flume:Cloudera开源的一套日志传输系统,和Scribe类似。我们在百度做的Minos,可以说是和Flume、Scribe类似,那为啥要重复造轮子?主要百度的数据源和服务器太多了,需要做许多功能来满足运维管理的问题。
5,Kafka:Linkedin开源的一套消息传输系统,和百度Bigpipe类似。我们Bigpipe开发了一半的时候,Kafka的论文发表了。Bigpipe会做去重,Kafka目前还没有这样的机制,需要自己去实现。两者都通过副本的机制,保证数据不丢。
Flume/Logstash/Beat 是同一类软件,如果抽象功能的话可以认为是一个插件执行器,有一些常用的插件(例如日志采集,Binlog解析,执行脚本等),也可以根据需求将自己的代码作为插件发布。
知乎靠谱答案
Kafka 一般作为Pub-Sub管道,没有抓取功能。一开始设计的时候主要是Jay Krep觉得Linkedin里面数据源,消费者之间关系太复杂,如果是N个数据源,M个消费者,需要拉N*M个线,并且接口和协议不同,所以使用了一种消息中间件来解耦数据源和消费者。但Kafka本身也不算消息中间件,中间件一般会有Queue和Topic两种模型,Kafka主要是Topic类的模型。
对搭建日志系统而言,也没什么新花样,以下这些依样画葫芦就可以了:
- 日志采集(Logstash/Flume,SDK wrapper)
- 实时消费 (Storm, Flink, Spark Streaming)
- 离线存储 (HDFS or Object Storage or NoSQL) + 离线分析(Presto,Hive,Hadoop)
- 有一些场景可能需要搜索,可以加上ES或ELK
小结
- 大概率采用Flume/kafka/hdfs(spark-ml)
- 重点关注部署与运维成本
数据建模/存储
多维数据模型
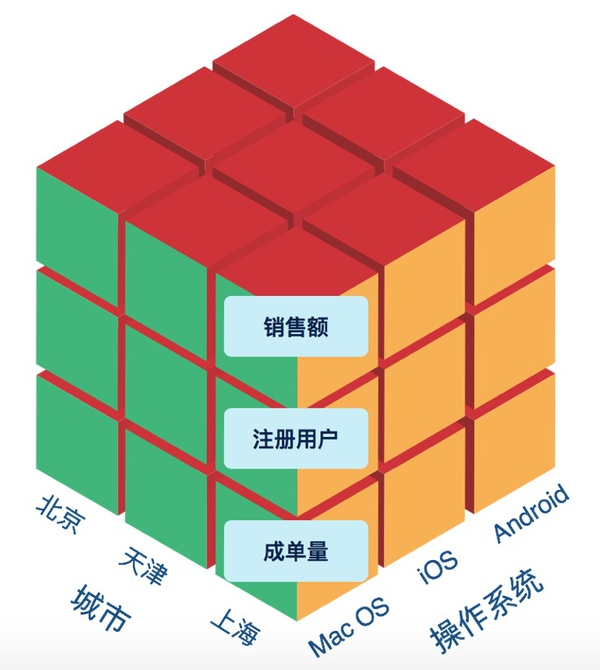
在互联网产品中,最重要的有两类数据——业务数据和用户行为数据。对于用户行为数据,我们可以讲用户的每一次操作理解为一个事件(Event),事件有个类型如提交订单、提出问题等,事件发生时有响应的上下文,如使用的操作系统、浏览器版本等系统属性,也有事件特有的如运费、订单价格等属性,这些属性就是一系列的维度,还有一部分是事件发生的用户ID。即:
Event Type + Properties + UserID
这里就形成了一系列的维度,描述的最细粒度的事件现场。通过UserID,我们还会关联到UserID这一维度的详情(User Profile),包括姓名、出生日期、身高、是否有小孩等。
ETL存储
做好数据源,减少ETL。
思考
对于智能化测试来说,一个用例的执行应该就是一个事件,事件的属性可以是通过与否、报错信息、执行时间等,UserID可以是模块或者用例id吧。建模还是需要仔细考虑的。
不过数据源和ETL应该都只有测试自己搞了。
数据统计、分析、挖掘
数据驱动
能不能做好数据,开放自助查询的功能?
查询模式:
- K-V(Key-Value)查询就是我们给出一个key,然后返回这个key相关的value内容。比如我们通过一个UserID,返回用户的一些画像信息,比如有没有房。再比如,通过UserID返回最近一段时间的详细访问行为序列。这里推荐使用HBase。
- OLAP(Online Analytical Processing)查询就是前面讲的多维数据分析,这里不赘述。可以使用的工具有InfoBright、Vertica、Impala、Redshift等。
- Ad Hoc查询就是有各种各样的不确定的需求,需要响应。这块可以用Hive,或者Spark SQL来满足,再不行就写程序自己实现吧。
- ES,支持一些模糊的查询
统计
- 哪个模块失败数最多
- 什么时间段执行最多问题
- 什么类型的报错最多
分析
- 用例失败原因
挖掘
- 协助写用例 (推荐步骤、类似用例)
- 推断模块稳定性
可视化与反馈
可视化
- 对接看板,提供数据或时序交互,有点像数据底座的功能
- Echarts或D3提供web版基本的可视化功能
- Tableau ?
整体数据流与架构图
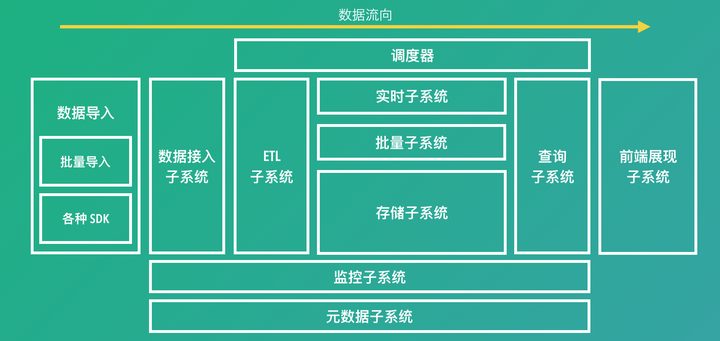
元数据和调度器分别是数据平台的心脏和大脑。
调度器
如果有很多请求的时候,需要优先级调度;(现在可能用不上)
如果请求有依赖的时候,使用DAG调度;(Azkaban可以完成)
元数据
开源实现可以参考Hcatalog,封装了hive meta。
元数据提供的服务 主要有三点:
- 数据的Schema:表、字段定义等。
- 数据的就绪状态:数据就绪时间、存放位置等动态信息。
- 元数据的访问API。
扩展的服务还包括:
- 权限控制(ACL):严格来说ACL不算元数据的一部分,但这两者关系太紧密,一般放在一起考虑。
- 元数据的变更记录:谁做了什么操作好做审计,另外可以有元数据的版本信息,这样对历史数据的存取更方便一些。
Hive on Spark 安装配置
hive on spark 安装配置
简介
网上的教程都说spark官网预编译的二进制文件含有hive部分,不能直接使用,需源码编译,包括hive的wiki也提及需要不含hive的jars。经过实践也可以通过剔除hive相关包,使用预编译的spark包完成hive-on-spark的部署。
环境
hadoop: 2.7.3
hive: 2.3.2
spark: 2.2.0
6个节点,4个nodemanager
hive 的wiki说只有对应的版本能保证兼容性,不是完全兼容也可以的。只是不知道有无隐患。
yarn配置
修改之后需要分发集群并重启
1 | vim /home/hadoop/soft/hadoop/etc/hadoop/yarn-site.xml |
hdfs准备路径和jar包
新建spark-log目录
hdfs dfs -mkdir -p hdfs://ns1/spark/spark-log
上传jar包
hdfs dfs -mkdir -p hdfs://ns1/spark/jars
hdfs dfs -put $SPARK_HOME/jars/*.jar hdfs://ns1/spark/jars/
spark配置
配置spark-env.sh、slaves和spark-defaults.conf三个文件spark-env.sh
1 | export SPARK_MASTER_WEBUI_PORT=8081 |
slaves 每行一个hostname或ip
1 | hd2 |
spark-defaults.conf
以下配置按照NodeManager是12C12G计算
1 | spark.master yarn |
拷贝到hive的配置目录,使调用hive时能识别使用spark-defaults.conf
1 | ln -s ~/soft/spark/conf/spark-defaults.conf ~/soft/hive/conf/ |
验证spark
1 | ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.2.0.jar 10 |
hive
添加必要的依赖库
1 | ln -s /home/hadoop/soft/spark/jars/scala-library-2.11.8.jar /home/hadoop/soft/hive/lib/ |
剔除spark中hive的库
1 | mkdir hive-jars |
启用spark引擎
1为临时方案,2为默认配置
- 在命令行交互(进入hive之后)
set hive.execution.engine=spark; - 配置hive.site.xml文件,配置
1
2
3
4
5
6
7
8
9
10<property>
<name>hive.execution.engine</name>
<value>spark</value>
<description>
Expects one of [mr, tez, spark].
Chooses execution engine. Options are: mr (Map reduce, default), tez, spark. While MR
remains the default engine for historical reasons, it is itself a historical engine
and is deprecated in Hive 2 line. It may be removed without further warning.
</description>
</property>
验证hive on spark
- 命令行输入 hive,进入hive CLI
- set hive.execution.engine=spark; (将执行引擎设为Spark,默认是mr,退出hive CLI后,回到默认设置。若想让引擎默认为Spark,需要在hive-site.xml里设置)
- create table test(ts BIGINT,line STRING); (创建表)
- select count(*) from test;
- 若整个过程没有报错,并出现正确结果,则Hive on Spark配置成功。
优化
因为在yarn上执行,拷贝spark的jars到hdfs上能避免每次拷贝。
如果仅是在hive中使用spark,可以在hive-site.xml中配置。由于在spark-defaults.conf已经配置过,这里可以不配置
1 | <property> |
其他
内网使用pip
离线安装pip包
pip安装
暂略
下载包而不安装
该命令会下载whl包,包括被依赖的包
pip install <包名> -d <目录> 或 pip install -d <目录> -r requirements.txt
pip install oauthlib -d .\oauthlib
新版pip: pip download -d DIR somepackage
安装全部包
pip install –no-index –find-links=DIR -r requirements.txt
内网使用
windows环境下,建立全局配置文件C:\ProgramData\pip\pip.ini
1 | [global] |
不知为啥,就算配置上trust-host、证书,在我司内网环境下用pypi的源依旧会报证书验证错误SSL3_GET_SERVER_CERTIFICATE。
Centos 离线安装通用方法(Docker为例)
原理
yum install有参数--downloadonly,可以只下载不安装,搭配--downloaddir=DLDIR参数可以下载依赖包,完成离线安装。
命令实例:
1 | # online machine: pwd --> /root |
1 | # offline machine: pwd --> /root |
docker实例
按照官网说明,使用以上命令,获得的rpm包,基于Centos7.0-1406系统
https://github.com/Tony36051/docker-installer/tree/master/RPM-based/docker-ce-17.12-CentOS-7.0-1406
root权限执行一下命令即可:
sudo sh install.sh
可能的坑
rpm包有重复、冲突,体现为在安装xxx包时候,依赖项Requires,但是有重复或冲突,需要卸载Removing,并被yyy包更新Updated。但是这个过程不能自动化,因为yum不知道你冲突后要保留哪个。例子如下:
1 | --> Processing Dependency: rpm = 4.11.3-25.el7 for package: rpm-libs-4.11.3-25.el7.x86_64 |
解决方法
- 查看重复包
1
2
3rpm -vqa | grep net-snmp-agent-
net-snmp-agent-libs-5.7.2-24.el7.x86_64
net-snmp-agent-libs-5.7.2-24.el7.i686 - 卸载冲突包
下面是卸载不符合系统的包,也有可能完把老版本全删掉,直接装新的1
yum remove rpm-libs-4.11.3-17.el7.i686
Zabbix 实践
Zabbix实践
安装
zabbix安装需要3大块,server负责整理数据,agent采集数据,web负责展示与GUI配置。
server和web都依赖关系型数据库,这里以mysql为例,也是docker形式。
1 | docker run --name mysql --restart=always \ |
Server端
1 | docker run --name zabbix-server-mysql --restart always \ |
Web端
1 | docker run --name zabbix-web-nginx-mysql \ |
Agent
Agent用原生的rpm包安装,centos7.2下直接安装无依赖。生产环境要离线安装,找到以下仓库 http://repo.zabbix.com/zabbix/3.4/rhel/7/x86_64/
笔者在编辑时候,版本号为3.4,zabbix-get-3.4.7-1.el7.x86_64.rpm
sudo rpm -ivh zabbix-get-3.4.7-1.el7.x86_64.rpm
默认路径
/etc/zabbix #配置
/var/log/zabbix #日志
sudo systemctl restart zabbix-agent.service #systemd 重启
配置
判断进程是否存在、获取进程号
使用UserParameter功能,能在agent端执行自定义命令,命令的返回值会送到server作为键值对应的数值。
流程
- 在Agent端/etc/zabbix/zabbix_agentd.d/目录下新建参数自定义命令。
1
2
3sudo vim /etc/zabbix/zabbix_agentd.d/userparameter_script.conf
UserParameter=ps[*],ps -ef | grep $1 | grep -v zabbix | wc -l
UserParameter=pid[*],ps -ef | grep "$1" | grep -v grep | sed -r 's/ +/ /g' | cut -d " " -f 2 - 在web端配置监控项,可以是active或passive,键值ps[NameNode],对应地会在agent端执行命令ps -ef | grep NameNode | grep -v zabbix | wc -l
- server端收到对应的返回值,正常来说是1。
Hadoop参数
流程
- server端执行外部检查,外部检查调用zabbix/externalscripts目录下执行系统命令(如调用 python get_dfs_info.py master1 50070)。
- 调用系统命令后,被调用程序应使用zabbix-sender给server端发送相关数据。
这里发送的是文本文件,每行一条记录,空格划分三列,第一列是被监控机器在web上显示的hostname,第二列是键值,第三列是具体的数据。 - zabbix-server监控项用zabbix采集器,键值对应发送文件的第二列,数据类型要区分整数和字符串等。
脚本
1 |
|
监控项 示例
外部检查:
1 | cluster-hadoop-plugin.sh ${HADOOP_NAMENODE_HOST} ${HADOOP_NAMENODE_METRICS_PORT} ${ZABBIX_NAME} DFS |
监控项
Zabbix采集器:键值live_nodes
如何调试
agent机器进入zabbix用户调试
如果需要在被监控机器执行脚本获取监控数据,可以使用UserParameter功能,Agent将会在被监控机器上以zabbix用户执行对应的命令。经常会出现权限问题等,调试时需要切换用户,以下是切换用户的命令:
sudo su -s /bin/bash zabbix
Ansible 注释或取消注释配置文件行
Ansible 注释或取消注释配置文件行
简介
使用replace或lineinfile文件处理多行或单行配置文件,进行注释或解除注释
原始文件
1 | cat /etc/zabbix/zabbix_agentd.conf |
注释
1 | cat config.yml |
取消注释
1 | cat config.yml |