背景
测试岗位却不甘止步于业务测试,遂尝试智能化测试,当前的思路是通过日志大数据分析,协助自动化用例的诊断和建议。
他山之石
《从日志统计到大数据分析》
知乎专栏作家桑文锋[http://SensorsData.cn](https://link.zhihu.com/?
target=http%3A//SensorsData.cn) 神策数据创始人&CEO
数据处理流程图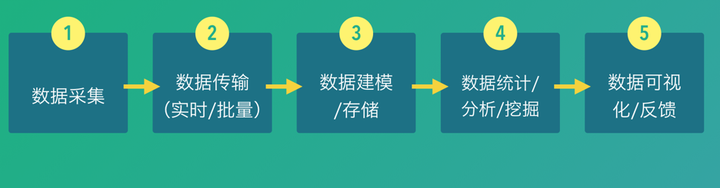
数据采集
- 全
多个来源、C/S(B/S) - 细
多个维度,ip、url、时间、userid等等尽可能多 - 数据格式
- Protocol Buffer:Google使用,较为重型
- JSON:学习成本低
- Thrift——由Facebook开源的一套开发框架和数据格式,相比PB,在解析效率上低点,但周边组件比较完善。
- Avro——由Hadoop创始人Doug Cutting主导开发的,使用接口上和Thrift类似,有客户公司在使用。
在简单看看文档后,估计会使用json。
- 数据类型
被测应用自身日志、环境日志(cpu、容器内env)、测试脚本日志;
应用代码、测试脚本(代码本身)
数据库数据?
数据传输
【这段完全照抄】
1,FTP:数据量小且时效性要求不高,用FTP是最省事的。
2,Sqoop:用于传统数据库和Hadoop之间的数据传输。3,Scribe:Facebook开源的一套日志传输系统,github上已经不维护了。
4,Flume:Cloudera开源的一套日志传输系统,和Scribe类似。我们在百度做的Minos,可以说是和Flume、Scribe类似,那为啥要重复造轮子?主要百度的数据源和服务器太多了,需要做许多功能来满足运维管理的问题。
5,Kafka:Linkedin开源的一套消息传输系统,和百度Bigpipe类似。我们Bigpipe开发了一半的时候,Kafka的论文发表了。Bigpipe会做去重,Kafka目前还没有这样的机制,需要自己去实现。两者都通过副本的机制,保证数据不丢。
Flume/Logstash/Beat 是同一类软件,如果抽象功能的话可以认为是一个插件执行器,有一些常用的插件(例如日志采集,Binlog解析,执行脚本等),也可以根据需求将自己的代码作为插件发布。
知乎靠谱答案
Kafka 一般作为Pub-Sub管道,没有抓取功能。一开始设计的时候主要是Jay Krep觉得Linkedin里面数据源,消费者之间关系太复杂,如果是N个数据源,M个消费者,需要拉N*M个线,并且接口和协议不同,所以使用了一种消息中间件来解耦数据源和消费者。但Kafka本身也不算消息中间件,中间件一般会有Queue和Topic两种模型,Kafka主要是Topic类的模型。
对搭建日志系统而言,也没什么新花样,以下这些依样画葫芦就可以了:
- 日志采集(Logstash/Flume,SDK wrapper)
- 实时消费 (Storm, Flink, Spark Streaming)
- 离线存储 (HDFS or Object Storage or NoSQL) + 离线分析(Presto,Hive,Hadoop)
- 有一些场景可能需要搜索,可以加上ES或ELK
小结
- 大概率采用Flume/kafka/hdfs(spark-ml)
- 重点关注部署与运维成本
数据建模/存储
多维数据模型
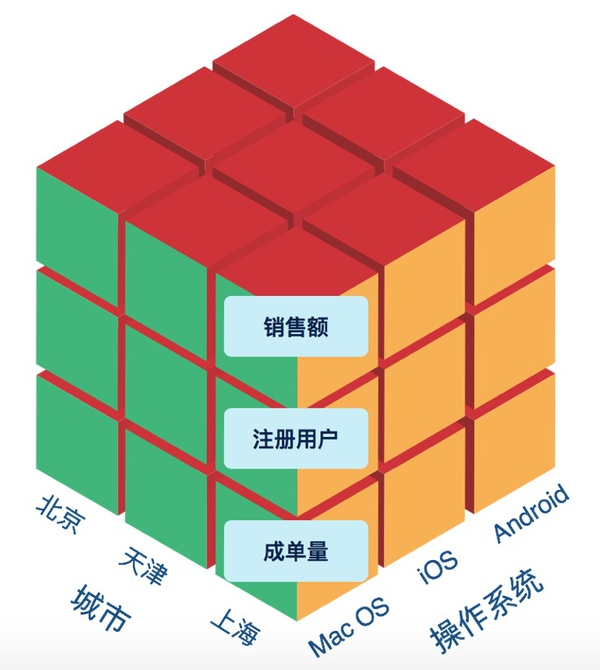
在互联网产品中,最重要的有两类数据——业务数据和用户行为数据。对于用户行为数据,我们可以讲用户的每一次操作理解为一个事件(Event),事件有个类型如提交订单、提出问题等,事件发生时有响应的上下文,如使用的操作系统、浏览器版本等系统属性,也有事件特有的如运费、订单价格等属性,这些属性就是一系列的维度,还有一部分是事件发生的用户ID。即:
Event Type + Properties + UserID
这里就形成了一系列的维度,描述的最细粒度的事件现场。通过UserID,我们还会关联到UserID这一维度的详情(User Profile),包括姓名、出生日期、身高、是否有小孩等。
ETL存储
做好数据源,减少ETL。
思考
对于智能化测试来说,一个用例的执行应该就是一个事件,事件的属性可以是通过与否、报错信息、执行时间等,UserID可以是模块或者用例id吧。建模还是需要仔细考虑的。
不过数据源和ETL应该都只有测试自己搞了。
数据统计、分析、挖掘
数据驱动
能不能做好数据,开放自助查询的功能?
查询模式:
- K-V(Key-Value)查询就是我们给出一个key,然后返回这个key相关的value内容。比如我们通过一个UserID,返回用户的一些画像信息,比如有没有房。再比如,通过UserID返回最近一段时间的详细访问行为序列。这里推荐使用HBase。
- OLAP(Online Analytical Processing)查询就是前面讲的多维数据分析,这里不赘述。可以使用的工具有InfoBright、Vertica、Impala、Redshift等。
- Ad Hoc查询就是有各种各样的不确定的需求,需要响应。这块可以用Hive,或者Spark SQL来满足,再不行就写程序自己实现吧。
- ES,支持一些模糊的查询
统计
- 哪个模块失败数最多
- 什么时间段执行最多问题
- 什么类型的报错最多
分析
- 用例失败原因
挖掘
- 协助写用例 (推荐步骤、类似用例)
- 推断模块稳定性
可视化与反馈
可视化
- 对接看板,提供数据或时序交互,有点像数据底座的功能
- Echarts或D3提供web版基本的可视化功能
- Tableau ?
整体数据流与架构图
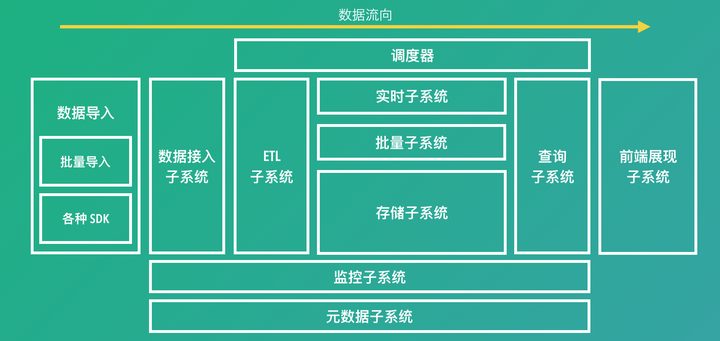
元数据和调度器分别是数据平台的心脏和大脑。
调度器
如果有很多请求的时候,需要优先级调度;(现在可能用不上)
如果请求有依赖的时候,使用DAG调度;(Azkaban可以完成)
元数据
开源实现可以参考Hcatalog,封装了hive meta。
元数据提供的服务 主要有三点:
- 数据的Schema:表、字段定义等。
- 数据的就绪状态:数据就绪时间、存放位置等动态信息。
- 元数据的访问API。
扩展的服务还包括:
- 权限控制(ACL):严格来说ACL不算元数据的一部分,但这两者关系太紧密,一般放在一起考虑。
- 元数据的变更记录:谁做了什么操作好做审计,另外可以有元数据的版本信息,这样对历史数据的存取更方便一些。

